
There’s a scene in Interstellar that I always think of, which goes like this… the crew is aboard the Endurance, orbiting Miller’s planet. They know that every hour on the surface equals seven years back on Earth, but they go anyway, because the mission demands it.
And while Cooper and Brand are wading through knee-deep water on a world drowning in tidal waves, (the above image) Romilly stays back, on the ship, for twenty-three years. Doing what he can with the time he has.
While reading through a research paper from MIT and NVIDIA’s Taming the Long-Tail: Efficient Reasoning RL Training with Adaptive Drafter, the thought of Romilly came back to me, again.
It’s a systems paper, which means it’s technically about GPU scheduling and speculative token generation. Yeah, not an easy read but then decoding such literature gives me a kick 🙂
So, how did the paper take me to Interstellar’s iconic scene?
I am always imaging/connecting science fiction with in-lab experiments, so here in this paper, I find the story of a computational crew where one member always, always finishes last. And everyone else just has to wait.
I’ve been reading and trying to make sense of AI reasoning models for a while now. My aim is to have at least surface level understanding of the training loops, the inference tricks, the system designs that make these things actually work at scale. So when I came across this paper, I didn’t just see benchmarks and speedup numbers. I saw a problem I recognized immediately. One I’d been vaguely aware of without ever fully articulating it.
The Long Tail Problem, or Why One Slow Thinker Holds Everyone Back
Let me set the scene.
You’re training a reasoning AI, something like DeepSeek-R1 or a model fine-tuned with reinforcement learning to solve competition math problems. The training loop goes something like this, you give the model a batch of questions, it generates responses, you score those responses, and then you update the model’s weights based on how well it did.
Simple and straightforward, but the part where the model actually writes its answers turns out to be the hidden bottleneck that kills efficiency.
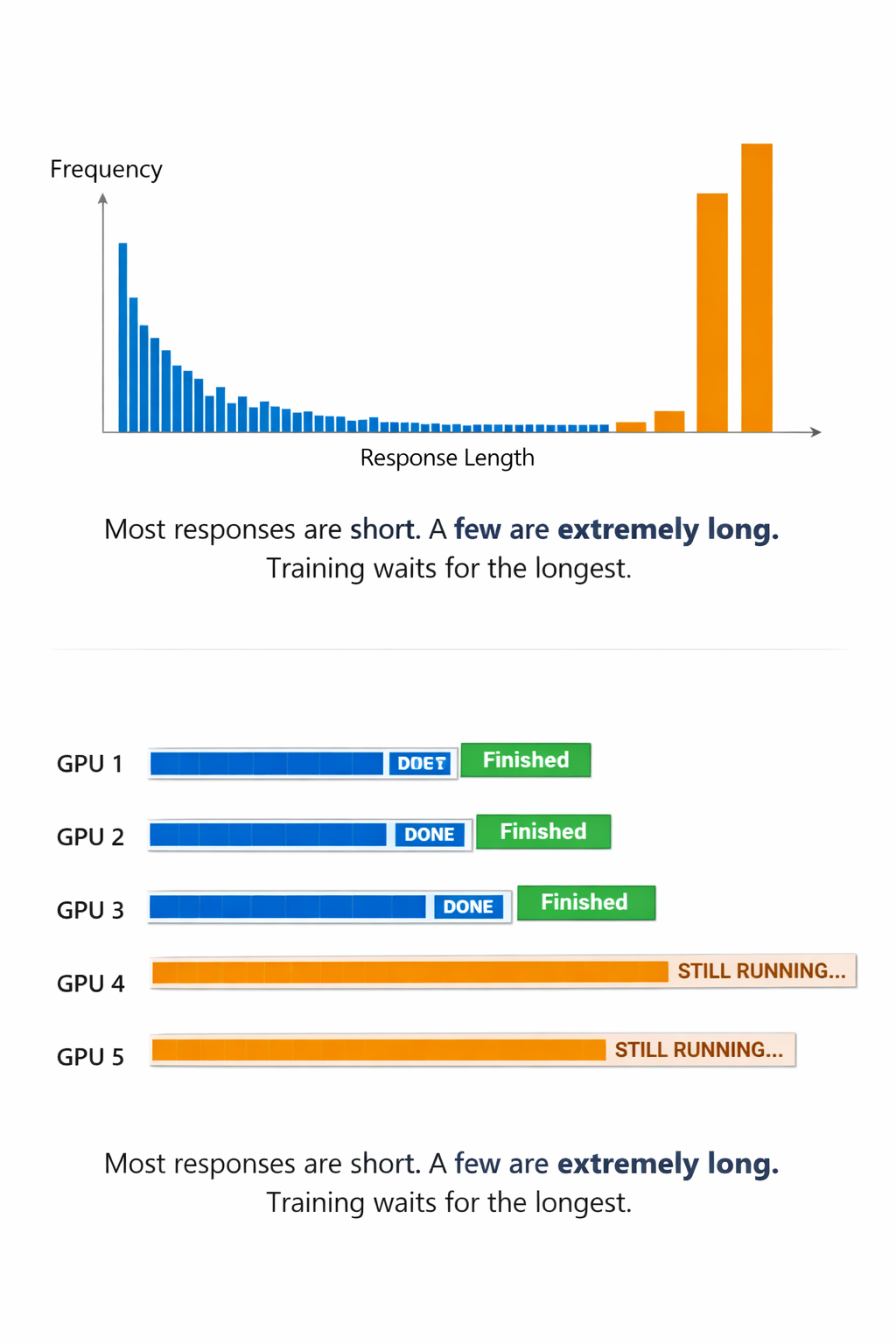
Most of the time, the model responds quickly, like when you ask a simple math question and it answers in just a few words. But sometimes, there’s an unusual question, like a really tough math problem that makes the model go through many steps, trying different ways to solve it, correcting itself along the way. These complicated answers can end up being very long, like tens of thousands of words. The problem is, because the system has to wait for that one long and complex answer to finish before it can move on and learn from the rest, it slows down the whole training process.
The researchers looked at how a large AI model trained on many computers over a long time. They found that most of the time, the AI’s responses are short, but sometimes, a few responses are very long and reach the maximum allowed length.
The difference between the typical short responses and these very long ones is huge. This means that a lot of computing power and money is being used to process responses that are often brief, but when a long answer is needed, the system spends a lot of time and resources on just a few cases. The result is a lot of idle time and wasted resources (GPUs & all that compute) waiting for those long responses to finish.
This is the long-tail problem. And it accounts for roughly 85% of training time in the rollout phase.
Speculative Decoding Is Just Structured Foresight
Here’s where the sci-fi lens helps me think.
In The Matrix Reloaded, the Oracle tells Neo what she thinks he needs to hear, not necessarily what she knows. She operates on incomplete information, making probabilistic bets about the future to nudge the system toward a better outcome. She’s not certain, she’s speculative. And critically, she acts before the verification comes.
Speculative decoding in AI works on almost exactly this principle. The standard way a language model generates text is sequential, that is,
produce one token, feed it back in, produce the next token, repeat.
It’s like a typist who has to read each word they just typed before writing the next one. Painfully sequential and painfully slow.
Speculative decoding breaks this by introducing a second, much smaller model, the draft model, that races ahead and guesses the next several tokens all at once. Then the big target model checks those guesses in a single parallel forward pass, accepting the correct ones and rejecting where the draft went wrong.
If the draft model is good, you might accept five or eight tokens at once instead of generating them one by one. You’ve essentially turned a memory-bound sequential process into a compute-bound parallel one, and on modern GPUs, that’s an efficiency win.
The researchers show that with a well-tuned draft model on a Qwen2.5-32B architecture, you can get over 3.5x speedup on individual decoding.
The remarkable part is that it’s mathematically lossless. The output distribution is identical to what you’d have gotten without the draft model.
Coming back to the Oracle’s guess, when verified and accepted, is exactly as good as if you’d generated it the slow way. You’re not sacrificing quality for speed. You’re just reorganizing the work.

Optimizing Against a Shifting Model
This is where I got confused at first when I tried to imagine using speculative decoding for reinforcement learning.
In normal inference, when a model is just answering questions, the main model doesn’t change. It’s fixed. So once you train a smaller draft model to imitate it, that draft model keeps working. The thing it’s trying to predict stays the same.
But reinforcement learning training isn’t like that.
During RL training, the main model is constantly changing. Every training step updates its weights. The model you’re drafting for right now is slightly different from the model you were drafting for a few minutes ago. And as training continues, that gap keeps growing.
This is what the researchers call the Evolving Target Model problem.
Your draft model slowly goes out of date. It was trained to guess the behavior of an older version of the target model. As the target improves, the draft’s guesses start missing more often. Fewer tokens get accepted. The whole speculative trick becomes less effective and can even waste compute if too many guesses get rejected.
It’s like trying to predict what someone will say while they’re actively changing their mind.
And that’s just the first problem.
There are two more.
First, training a good draft model isn’t free. You usually need a special architecture, something lightweight that can plug into the main model’s internal states, and training it requires extra computation. So you’re adding overhead before you even see speedups.
Second, RL training has messy, uneven batch sizes. At the beginning of a rollout, you might have many sequences generated at once. But as shorter responses finish, the batch shrinks. And speculative decoding behaves very differently depending on batch size. What works beautifully when you’re generating one sequence at a time might hurt performance when you’re generating dozens in parallel.
So now you have three problems tangled together:
- The target model keeps changing.
- The draft model is expensive to train.
- The efficiency depends heavily on batch size.
The researchers built a system, called Taming the Long Tail, (TLT) to handle all three at once.
Using the Time That Would Have Been Wasted
What I really like about TLT is that it doesn’t try to eliminate the long tail. It works with it.
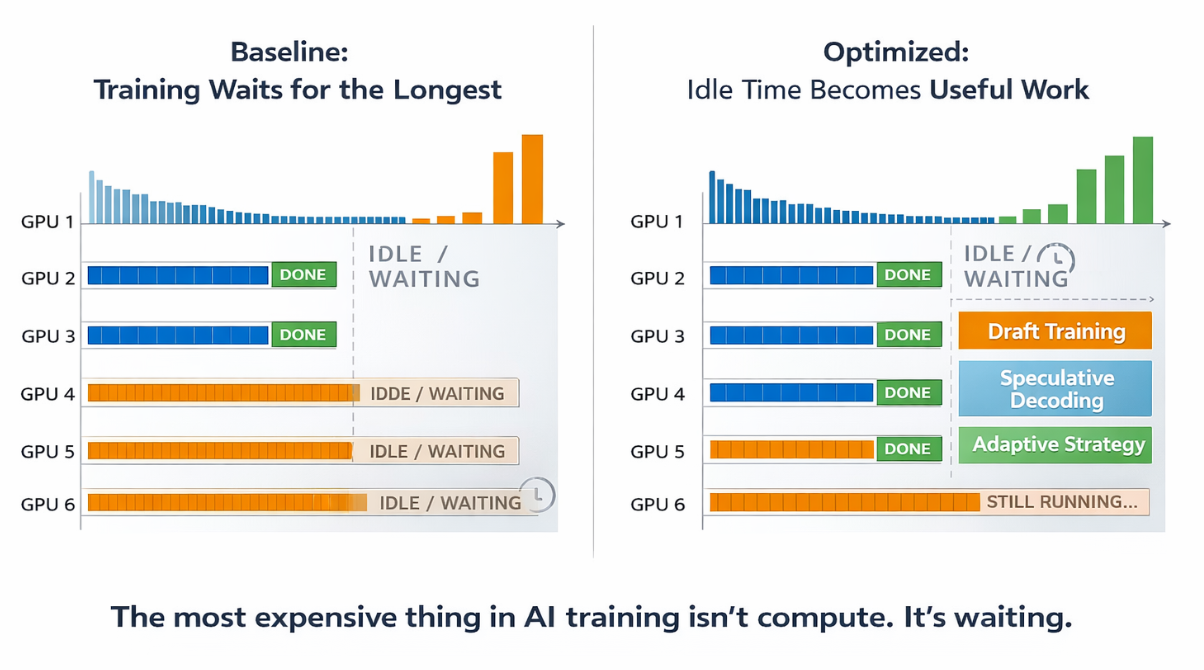
Let’s say, you have five workers, or five groups of GPUs, generating responses during training. At the start, all of them are busy. But pretty quickly, some responses finish. Worker 3 is done. Then Worker 4. Then Worker 5.
Workers 1 and 2 are still stuck handling those really long responses that take forever.
In a normal setup, Workers 3, 4, and 5 would just sit there doing nothing. Their job is done, so they wait.
TLT looks at that waiting time and says, that’s not dead time, that’s usable time.
The researchers call these idle periods “rollout bubbles”. They aren’t rare accidents, they happen every training step because long responses are a consistent pattern. So instead of ignoring those bubbles, TLT fills them.
When a worker finishes early, the system automatically gives it a new temporary job, something like, help train the draft model. This extra job runs quietly in the background. It’s low priority and can be stopped at any time. When the main training step is ready to move forward, the background job pauses and everything continues as normal.
So nothing important gets delayed. The idle time just gets recycled.
There’s another clever piece. The draft model needs access to the target model’s hidden states to train properly. But those hidden states are already being computed during normal generation. So TLT simply saves them and reuses them. No extra forward passes. No duplicate work.
This means the draft model is always training on real, up-to-date data from the current version of the target model. It doesn’t fall behind.
There is one small complication. The workers that finish early usually handled short responses. If you only train on those, the draft model might get bad at predicting long responses. To fix that, TLT keeps a small buffer of longer sequences from the previous step and mixes them in. They’re slightly out of date, but close enough. The draft model doesn’t need perfect accuracy, it just needs to stay roughly aligned.
The end result is simple but powerful:
the draft model stays in sync with the constantly changing target model, and it does so using time that would have otherwise been wasted.
That’s the part I find beautiful.
No extra hardware. No dramatic redesign. Just better use of the time the system already had.
When Optimization Becomes a Game
The third piece of the system, the Adaptive Rollout Engine, is where it gets almost gamified in a way I find hard not to enjoy.
Speculative decoding isn’t just one switch you turn on. It comes with a bunch of settings. For example:
- How many tokens should the draft model try to guess ahead?
- How many of those tokens should the big model verify at once?
- How wide should the draft branching be?
These choices matter a lot. The paper shows that if you tune them well, you might get a 2–3x speedup. If you tune them badly, you might get no speedup at all.
So instead of hard-coding these settings, TLT lets the system figure them out on its own.
It uses something called a “multi-armed bandit” algorithm. The name sounds complicated, but the idea is simple.
Imagine you’re standing in front of a row of slot machines. You don’t know which one pays out the most. You could keep pulling just one lever, or you could try different machines to see which one works best. Over time, you learn where to put your money.
That’s basically what this algorithm does.
Each “slot machine” is a different speculative decoding setup, a specific combination of draft depth, number of tokens to verify, and so on. The system tries different setups and measures how well they perform. The “reward” is how efficiently tokens were generated, basically, how much useful work got done per unit of time.
Most of the time, it uses whatever configuration has been working best recently. But every so often, it tries something different, just in case conditions have changed.
There’s another smart detail. The best settings depend a lot on batch size. When you’re generating many sequences at once, memory pressure changes. A strategy that works great for a small batch might be terrible for a large one.
So TLT groups strategies into “buckets” based on batch size. Configurations only compete against others in the same bucket. That way, the system isn’t comparing apples and oranges.
And there’s one more safety net.
Early in training, the learned draft model might not be very good yet. So TLT includes a backup option: a simple n-gram retrieval method. It builds a small lookup table of common token sequences from recent outputs and uses that to guess ahead. It’s not fancy, but it works immediately.
So from the very first step of training, speculative decoding can still provide some speedup, even before the draft model has fully caught up.
Altogether, this part of the system feels less like a fixed rulebook and more like something that adapts as it goes. It experiments, keeps score, and gradually settles on what works best in the current moment.
Speed Without Changing the Outcome
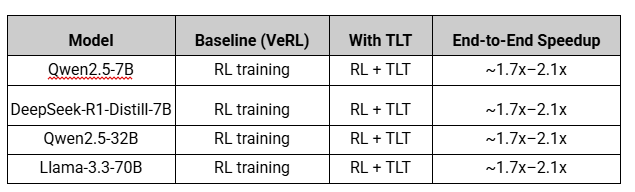
The evaluation results are strong across every model they tested:
- Qwen2.5-7B
- DeepSeek-R1-Distill-7B
- Qwen2.5-32B
- Llama-3.3-70B
Compared to VeRL, ByteDance’s RL training framework, TLT consistently speeds things up.
Here’s the high-level picture:
And these gains show up:
- On H100 GPUs
- On A100 GPUs
- At different cluster sizes
- Across different model scales
That consistency is important. This isn’t a narrow benchmark trick.
Even more important is, the reward curves for VeRL and TLT almost perfectly overlap.
That means the model learns the same thing. The final quality doesn’t change, which also means, the adaptive draft model doesn’t distort training. It just makes the process faster.
Speed changes. Learning doesn’t.
There’s also a nice side effect.
When training finishes, you don’t just have your final reasoning model. You also have a well-trained draft model that stays aligned with it the entire time. That draft model can now be used to speed up inference in production.
So you paid for one training run, and got two useful models out of it.
To understand what a 1.7x–2x speedup means in practice, the paper includes a real trace from ByteDance: 385 training steps took 11 days on 128 GPUs.
Cut that in half and you’re looking at roughly 5.5 days instead of 11.
At datacenter GPU rental rates, that’s not a small difference. Multiply that across large clusters, across many training runs, across the entire industry, and this kind of systems optimization starts to matter a lot.
Takeaway
I keep coming back to Romilly. Twenty-three years on the ship, waiting. In the movie, it’s treated as a tragedy. But another perspective is, he spent those years studying the wormhole data, doing science, using the time he had. He didn’t waste the wait.
The researchers at MIT and NVIDIA looked at idle GPUs during long-tail RL rollouts and saw the same thing. Not wasted time, training time, in disguise. The adaptive drafter learns while the main model thinks. The slow thinker in the batch doesn’t hold the whole system back anymore. Everyone finds something useful to do.
Downtime got converted into something. The system got smarter in the gaps between the hard problems.
TLT is a paper about GPU scheduling and speculative decoding. But read generously, it’s also about not wasting the pauses. About making the inevitable inefficiency of hard thinking into an opportunity instead of a cost.
I’ll be thinking about that for a while.
Credit: MIT News
Paper: Taming the Long-Tail: Efficient Reasoning RL Training with Adaptive Drafter
Frequently asked questions
1. What is the long-tail problem in reinforcement learning training?
In RL training for reasoning models, most generated responses are short, but a small number are extremely long. Because training steps must wait for the longest sequence in a batch to finish, these rare long responses dominate total rollout time. This creates idle GPUs and significant inefficiency, often accounting for the majority of training time.
2. What is speculative decoding?
Speculative decoding is a technique that uses a smaller “draft” model to predict multiple tokens ahead. A larger “target” model then verifies those predictions in parallel. If the predictions are correct, multiple tokens are accepted at once, significantly speeding up generation without changing the output distribution.
3. Why is speculative decoding difficult to use during RL training?
Unlike inference, RL training constantly updates the target model’s weights. This creates the “Evolving Target Model” problem: the draft model quickly becomes outdated, reducing token acceptance rates and eliminating speed gains unless it is continuously retrained and kept aligned.
4. What is TLT (Taming the Long Tail)?
TLT is a system designed to make speculative decoding practical during RL training. It:
- Retrains the draft model continuously using idle GPU time
- Adapts speculative decoding strategies dynamically
- Handles changing batch sizes efficiently
This allows it to maintain speedups even as the target model evolves.
5. How much speedup does TLT provide?
Across models like Qwen2.5-7B, DeepSeek-R1-Distill-7B, Qwen2.5-32B, and Llama-3.3-70B, TLT achieves roughly 1.7×–2.1× end-to-end RL training speedup compared to VeRL, without degrading training rewards or final model quality.
6. Does TLT change what the model learns?
No. The reward curves between TLT and baseline RL training overlap almost perfectly. TLT does not alter the learning objective or training outcome. It only reduces wasted time during rollout, making training faster without affecting model quality.


